
בית לפודקאסטים, שיחות ועומק טכנולוגי בעברית.
כאן מתאספים כל הפרקים של רברס עם פלטפורמה — עם סיכומים, קישורים וכל מה שצריך כדי להעמיק.
האזנה לפרק האחרוןהפרק האחרון
פרקים אחרונים

516 - Carburetor 41 Open source and agentic coding
515 - Bumpers 91

514 - Attack Analytics
513 - Hebrew PDF at AI21Labs

512 - Carburetor 40

511 AI Protection and Governance with Nimrod from BigID

510 Federated Learning with Tal from Rhino
509 Bumpers 90

508 Controlled image generation with Misha from Bria.ai

507 Catburetor 39 Google and AI

506 ML Infra with Itai from MIND

505 Bumpers 89
504 Functional programming with Daniel Beskin

503 Bumpers 88

502 - Carborator 39

501 Bumpers 87

499 FE Containerization with Myops

498 with Niv from Hailo

497 AI-HR

496 Bumpers 86

495 ML Democratization, Yuval from Voyantis

494 SoLead and RS

493 Accessibility with Asaf from Evinced

492 Podcast about Ella, the AI assistant at One-Zero bank

491 Precise GenAI for Finance, with Oded from Datarails

490 K8s with Erez from Komodor

489 carburetor 38

488 Developing with LLMs securely, with Guy from Pillar

487 Bumpers 85

486 SaaS product alongside an on premises with Omer from Pentera

485 Ivrit

484 Architect WTF with Shai Yallin and Ron Klein

483 Training of foundational models with Ofir Bibi Lightricks

482 Bumpers 84

481 ML for insurance with Dror Lederman from honeycomb

480 Developer-Manager-Developer-Manager with Roi Ronn Hello Heart

479 Durable distributed workflows with Eric from Remitly

478 with Haim Yadid, Software in young startups

477 Exploits with Moshiko from Upwind

476 ML Explainability and friends with Dagan from Citrusx

475 Jamba with Hofit from AI21

473 Product thinking for devs with With Hila Fox

472 Bumpers 83 - Nostalgia

471 Notifications at scale with Gal Barak

470 Carburetor 37 Open Source שלום לתמימות

469 Software development in early stage startups with Shai Yallin

468 Crypto With Arik from Fireblocks

467 Passkeys with Rooly from OwnID

466 With Itamar from Codium

465 Carburetor 36, edge

464 Managing Critical Infrastructure with Gur from Cato

463 Synthetic data generation at ActiveFence

462 When and why should you platformize your product? With Guy and Eliran from Melio

461 Bumpers 82

460 Fuckups driven development with Liran from Lili

459 Bumpers 81

458 MAX-IMPACT with Gabriel Bilczyk

457 Tech Debt with Gidon from Redis

456 Carburetor 35 Hitech as a means to reduce social gaps

455 DBT with Chaim Turkel

454 The economics of governmental sites with Ran Bar-Zik

453 A payment journey in a FinTech company

452 Carburator 34
451 Structuring dev orgs with Daniel Kandel
450 What is an ML Engineer, with Or from Superwise

449 Bumpers 80

448 Synthetic data generation for Computer Vision models with Orly Zvitia

447 NLP challenges with Inbal Horev from Gong

446 Securing web APIs

445 Carburetor 33 - platform engineering

444 GPU databases

443 Hiring for strength, not skill with Sahaf from Hippo

442 With Mor Shamir about management in tech, families and teams
441 Datascience workflow with Yuval from AppsFlyer

440 Bumpers 79

439 Bringing offline to online data with Erez from Easy

438 With Philip from Deepchecks about OSS GTM
437 Refactoring (and Observability) with Omer van Kloeten

436 How to reach retirement as a software developer with Bentzy Lupu

435 Optibus Playback with Eitan Yanovsky

434 Parenting and Managing with Tony Felik Arad

433 Breaking Down Observability with Nitay Milner

432 Carburetor 32: 2022 DevOps Predictions
431 Multirepo at outbrain

430 Bumpers 78
429 Terminal 7 with Benny Daon

428 Jarvis with Sagi from Perimeter 81

427 DevOps Reloaded with Yair Etziony

426 Bumpers 77

424 Melio’s payment processor

423 B2D with Asi from Cloudinary

422 Pentesting with Erez Metula

421 The Cost of Cloud, a Trillion Dollar Paradox with Martin Casado

420 Bumpers 76

419 Navigation @Waze

418 Carboretor 31 Cost of cloud paradox

417 Developer Growth with Barak Yoresh from Lightricks

416 State Management in React
415 Bumpers 75

414 Cloud Native Challenges with Liran from Rookout

413 GitOps with Yaron from Soluto

412 Serverless at Via
411 Bumpers 74
410 Bumpers 73

409 ML Real World Usage with Noam from Pecan

408 Iterating Fast in Regulated Environment

407 Developer productivity tools with Daniel from Acumen

406 Smart software delivery with Yishai Beeri from LinearB
405 Bumpers 72

404 Securing Network Protocol with Tal Ravid from Armis

403 Carburetor 30

402 Writing Books with Miki Tebeka
401 AutoML at outbrain with Assaf Klein
400 Bumpers 71
399 Bumpers 70

398 with Danny Grander from Snyk
397 Bumpers 69

396 Magal with Ram Rotbart

395 Securing Critical Infrastructure

394 Rancher with Lior Kesos

393 Bumpers 68

392 Podcast with Asaf from VIM

391 Carburetor 29 - 3rd generation automation

390 Bumpers 67
389 With Roy Osherove CD/XP in the enterprise
388 Remote Work (Coronavirus special) With Shlomi Noach

387 Bumpers 66

386 Building internal products
385 Bumpers 65

384 Carburetor 28 - 2020 predictions
383 Bumpers 64

382 Carburetor 27 - k8s and multi-cloud
381 Bumpers 63
380 Bumpers 62

379 Building lightweight apps with Dekel Naar

378 Intuitive codebases with Omri Fima
377 Bumpers 61

376 PySnooper
375 Bumpers 60

374 Measuring Developers with Boaz Katz from Bizzabo

373 The Public Knowledge Workshop

372 Zadara
371 Bumpers 59

370 ThetaRay and Unsupervised Learning
369 Bumpers 58

368 Kubernetes and Dyploma at outbrain

367 Guilds at Outbrain

366 Clicktale, tech stack story

365 Carburetor 26 - open source politics
364 Bumpers 57
Summit 2018: After analyzing 30,000 SQL queries, these are the top mistakes developers make / Tomer Shay Shimshi
Summit 2018: Evolution 3.0 : solve your everyday problems with genetic algorithm / Mey Maayan Akiva

363 GPU @ Nvidia

362 Elastic, distributed corporate with Uri Cohen
361 Bumpers 56
358 Bumpers 55 - Nostagia
Summit 2018: Making Quick Decisions / Zohar Lerman
Summit 2018: A ballad to a programmer (בלדה למתכנת) / Yoni Tsafir & Iftach Bar
Summit 2018: Master the Art of the AST (and Take Control of Your JS!) / Yonatan Mevorach
Summit 2018: REST in peace? - cause APIs are much more than REST / Yonatan Maman
Summit 2018: Keep interviewing and nobody explodes: How WeWork uses games as part of our hiring / Yonatan Bergman
Summit 2018: Beyond the point estimate: uncertainty in neural networks for recommendations / Yoel Zeldes

360 Via
Summit 2018: Monitoria - A Monitoring Democracy / Yaron Idan
Summit 2018: Gain velocity by switching to Safe Mode / Vlad Ioffe
Summit 2018: Open-source: A Love/Hate Relationship / Uri Shamay
Summit 2018: Breaking into my 3D Printer's Firmware / Uri Shaked
Summit 2018: Daddy, where is my Arduino? / Uri Nativ & Roni Nativ
Summit 2018: How shit works: Time / Tomer Gabel

359 Serverless with Erez Berkner from Lumigo
Summit 2018: When S.O.L.I.D met front-end components / Shiri Haim
Summit 2018: There is no B2B experience / Shani Brusilovsky
Summit 2018: Let's talk about THEIR salaries / Shahar Kedar
Summit 2018: Same same, but different: Lessons learned from building the same feature twice a 1Y/ Shachar Brenner
Summit 2018: How I built the fastest graph database on earth / Roi Lipman
Summit 2018: I did a PhD in computer science in order to work with human beings / Reuth Mirsky
Summit 2018: Creating a Product Your Users Will Love / Reut Golan
Summit 2018: Web security / Ran Bar Zik
Summit 2018: Storing your data in the cloud: doing it right / Orit Wasserman
Summit 2018: How to Find Growth Material & Learn x2 Faster / Oren Ellenbogen
Summit 2018: Progressive Web Applications and an Offline First Mentality / Omer Goldberg
Summit 2018: Lean Startup in Action / Nissim Tapiro
Summit 2018: Deeper Than Abstractions (Let’s Dive into Source Code!!) / Netta Bondy
Summit 2018: Analysis of Direct and Local Deep Neural Networks for Quantum Atomic Forces / Nataly Kuritz
Summit 2018: 7±2 Reasons Psychology Will Help You Write Better Code / Moran Weber & Jonathan Avinor
Summit 2018: Developers' Communities: Building your Personal Brand and Creating Real Impact / Morad Stern
Summit 2018: Devs are from Mars, Managers are from Venus: How to convince your CEO better code.../ Michael Shalyt
Summit 2018: Event Sourcing Scaling - Pay Less, Do More / Michael Feinstein
Summit 2018: Being a Generalist Developer - is it for you? / Lital Hassine
Summit 2018: UX/UI and the Trusting Brain / Jonathan Saring
Summit 2018: Software engineers - let's crash the Deep Learning party! / Jenny Abramov
Summit 2018: Career growth hack: See what other don't, Fix what other fear! / Itiel Shwartz
Summit 2018: Shifting Sec to the Left with Conjur Open Source / Inbal Zilberman Kubovsky
Summit 2018: Micro Frontends Architecture & in practice / Idan Levin
Summit 2018: The magic of distributed systems: when it all breaks and why / Holden Karau
Summit 2018: The Hall of shame / Sohar Sacks & Ido Viron
Summit 2018: Your Next Game - Built by React / Eyal Eizenberg
Summit 2018: Less is more: how we cut off 30% of our code that did nothing without trying to / Gilad Ben Yossef
Summit 2018: Building Bit: Lessons Learned In The Trenches / Gilad Shoham
Summit 2018: Feature, we need to talk / Gil Vind
357 Bumpers 54
Summit 2018: Winning 2048 Game Using Deep Reinforcement Learning / Eyal Altshuler
Summit 2018: Quotes and Adages every developer must know / Erez Lotan
Summit 2018: How I Built Klarna's Experimentation System, and a LISP / Dotan Nahum
Summit 2018: Don't be a freelancer / David Weinberg
Summit 2018: Stackoverflow, the vulnerability marketplace / Danny Grander
Summit 2018: Don't Panic! (even if you get some really crazy data science project) / Dana Averbuch

356 Developers for NGO
Summit 2018: Sequence Alignment for Ride Sharing / Dalya Gartzman
Summit 2018: The Open Source Development Surprise / Benjamin Gruenbaum
Summit 2018: We don't need no labels: the future of pretraining and self-supervised learning / Bar Vinograd
Summit 2018: Keeping it real - a practical guide to identifying fake news / Ayelet Dekel
Summit 2018: To DB or not to DB, or, Why Databases are like Religions / Amit Lichtenberg
Summit 2018: Going Full Rewrite - The Incremental Way / Alex Badyan
Summit 2018: What I learned from 10 Yrs of "playing" with Neuroevolution - / Al Yaros

355 Technology Trends with Assaf Natanzon
354 Bumpers 53

353 Istio
352 Momento with Genady Okrain
351 Bumpers 52
350 Bumpers 51 for kids

349 WhiteSource

348 ZipRecruiter with Yaniv Shalev
347 Bumpers 50

346 Transparency @ Monday.com

345 carburetor 25

344 Power in Diversity with Galit Desheh
343 Bumpers 49

342 Optibus
341 Bumpers 48

339 JAMStack

338 Reversim and Cloudtalk

340 Serverless With Adam Matan
337 Bumpers 47
336 Bumpers 46
Summit 2017: DevTools and Headless Chrome - The Automation Power-Couple / Yonatan Mevorach
Summit 2017: Future of Serverless / Yoav Abrahami
Summit 2017: It ain't necessarily so! / Victor Bronstein
Summit 2017: Build a High-Performance Microservices Architecture with NATS.io & Golang / Uri Shamay
Summit 2017: Reactive Brain Waves / Uri Shaked
Summit 2017: Look at My Slides! / Uri Nativ
Summit 2017: An Abridged Guide to Event Sourcing / Tomer Gabel
Summit 2017: The Hall of Shame
Summit 2017: Orchestrator: MySQL high availability and management / Shlomi Noach
Summit 2017: Open Source Maintainership: musing and ranting / Shlomi Noach
Summit 2017: Smart replies, dumb people / Shira Weinberg
Summit 2017: Do we need yet another web framework / Shimi Bar
Summit 2017: Digital Culture/Clutter / Sheizaf Rafaeli
Summit 2017: With great data comes great responsibility... / Shay Palachy
Summit 2017: A little trust goes a long way... / Shay Palachy
Summit 2017: The Performance Investigator's Field Guide / Sasha Goldshtein
Summit 2017: Fundraising red flags: what (Israeli) startups keep failing at ... / Royi Benyossef
Summit 2017: Deep Work for programmers / Pavel Brodsky
Summit 2017: Moving Fast At Scale / Randy Shoup
Summit 2017: From Developer to Data Hacker / Omri Fima
Summit 2017: No forks, One star. Now what?! — How I published my Kotlin Open-Source lib / Ohad Shai
Summit 2017: Mistakes and Biases in Understanding Data / Omer Nevo
Summit 2017: The Secret Life of Side Projects / Ofir Dagan
Summit 2017: 10 Things I hate about you BE developers (with love, FE) / Noam Antebi
Summit 2017: Programming IS(!) Philosophy / Nir Rubinstein
Summit 2017: What do we care about? / Nir Kriss

335 Bumpers 45
Summit 2017: One platform to rule them all / Moshe Eshel
Summit 2017: A David vs. Goliath Tale of Triumph / Nati Shalom
Summit 2017: How hackers destroyed Mat Honan's life / Moria Ahi Mordehai
Summit 2017: The ultimate 5 min practical guide on how to casually chat with the people... / Michal Brosh
334 Carburetor 24: Outbrain's fabric network
Summit 2017: Lock Picking for Hackers / Michael Sverdlin
Summit 2017: Managing people? Lead them to engagement. One manager’s journey... / Lior Lavi
Summit 2017: Midburn: How we created an open source community / Lior Kaplan
Summit 2017: Effective Software Design (ESD) / Lior Bar On
Summit 2017: The Greatest Success Stories in History - are Inventions that Almost didn’t Exist / Jenny Abramov
Summit 2017: איך באג בשער של החניון של הקלפי כמעט עלה לאבי גבאי בפריימריז / Itai Friendinger
Summit 2017: Cross Region Data Replication - Design Considerations / Itai Friendinger
Summit 2017: The Interview Song / Iftach Bar & Yoni Tsafir

333 Nuclio with Yaron Haviv

332 Data infrastructure at Juno with Uri Shamay
Summit 2017: Let's talk about your salary / Iftach Bar
Summit 2017: The Freelancer Journey / Haim Yadid
Summit 2017: Being a remote site doesn’t have to suck / Hagai Levin & Noy Gabay
Summit 2017: A World without WhatsApp's Blue Lines / Gil Vind Picciotto
Summit 2017: Swarm Intelligence and Emergent Behavior / Eyal Gruss
Summit 2017: Building a Product That Both Your Grandma and Chuck Norris Can Use / Eynav Dagan
Summit 2017: Chaos Drills FTW - Introducing GomJabbar / Eran Harel
Summit 2017: Automate Your Review Process / Eliran Bivas

331 with Randy Shoup about Data science and experimentation at scale (english)

330 with Shir Meir about PyData etc

329 Bumpers 44
Summit 2017: Graph computation framework for SPARK / Elior Malul
Summit 2017: Saving up for technical debt - how to prepare so you don't go bankrupt / Elad Amit
Summit 2017: Searching Billions of Documents with Redis / Dvir Volk
Summit 2017: Open for Business: How Thinking "Productly Open" Will Save You Time / Danny Albocher
Summit 2017: Slaying the dragon - How to re-write a monolith into micro services and stay alive / Dalia Simons
Summit 2017: From zero to hero in 30 minutes: Serverless GraphQL/React... / Dafna Rosenblum
Summit 2017: Augmented Reality in Reality / Bar Fingerman
Summit 2017: To err is human: Introduction to modern safety thinking / Avishai Ish Shalom
Summit 2017: From 1x to 10x - A personal growth program... / Avi Etzioni & Sivan Franko
Summit 2017: Wikipedia's Democratic Structure / Agam Rafaeli
328 The tension between Agility and Ownership
Summit 2017: Baptism By Fire - why production issues make you a better developer / Adi Belan
Summit 2017: Redis Modules and The Joy of specificity / Adam Lev Libfeld
Summit 2017: Cheat, Scale, Win / Adam Lev Libfeld
Summit 2017: Detection of malicious footprints in large scale DNS traffic / Ada Sharoni
327 Bumpers 43

326 She Codes

325 Bumpers 42
Reversim Summit 2017 - Registration
Summit 2016: How I learned to speak Vulcan / Michal Tirosh
Summit 2016: The Subtle Dynamics Of Leading Without Authority As A Technical Lead / OREN ELLENBOGEN
Summit 2016: Anomaly detection in big data sets / David Gruzman
Summit 2016: From 400 bugs to 0 in 2 weeks - What we found below the "Static Analysis hood" ... / Yonatan Maman
Summit 2016: self.reproduce! / Inbal Galai
Summit 2016: Can Sci-Fi movies predict the future? / Hagai Levin
Summit 2016: Coderetreat - What, Why and How / Erez Lotan
Summit 2016: Flush your head! - an HTTP performance optimization tool / YONATAN MEVORACH
Summit 2016: How to Build a Micro-services Infrastructure In 7 Days / Gil Tayar
Summit 2016: Fund Raising 101 - Experiences Written in Blood... / Yuval Kaminka
Summit 2016: Reverse Engineering the "Human API" for Automation and Profit / Nati Cohen
Summit 2016: Ja-WAT? / ALLON MUREINIK
Summit 2016: Hardware Transactional Memory - Why You Should Care / URI SHAMAY
Summit 2016: From Quality Assurance to Quality Enablement / Amit Roseberger
Summit 2016: A shallow introduction to deep learning / Eyal Gruss
Summit 2016: How we ditched our apps for a chatbot / Eyal Yavor
Summit 2016: How to make kids excited about programming / Iftach Bar
Summit 2016: User Research: Digging for Gold / Kaleb Loosbrock
Summit 2016: Measuring and monitoring client side performance / Nir Nahum
Summit 2016: Functional Programming Paradigms in Software Architecture / Nir Rubinstein
Summit 2016: Programing, stress and mindfulness / Noam Elfanbaum
Summit 2016: Open Source / Re:dash - from a side project to business / Arik Fraimovich
Summit 2016: Open Source / Open Source Newbie: An Amazing Story of Overcoming Very Minor Obstacles / Eyal Allweil
Summit 2016: Open Source / HebMorph - Hebrew made searchable / Itamar Syn-Hershko
Summit 2016: Open Source / Organizing an open-source conference and living to tell the tale / Tomer Brisker
Summit 2016: THIS _IS_ YOUR JOB / Shai Kfir
Summit 2016: MicroApps Architecture -- The way to do microservices for web apps / Yonatan Maman
Summit 2016: Cloud Patterns / Tamir Dresher
Summit 2016: Good rules for building a bad Android app / Shem Magnezi
Summit 2016: Rise of the (content) chat bots - how NLP, search and recommendations play together / Shaked Bar
Summit 2016: Journey to the Realtime Analytics in Extreme Growth / Yulia Trakhtenberg
Summit 2016: DevOps paradigm in R&D day-to-day / Adi Shacham-Shavit
Summit 2016: 10 Real problems and solutions for your Build & Deploy process / Ariel M. Moskovich
Summit 2016: "Operations" - you keep using that word, but I don’t think it means ... / Avishai Ish-Shalom
Summit 2016: You're great at writing code. You need to be greater at telling stories / Boaz Gaon
Summit 2016: Simple, Battle Proven, Microservices Strategy / Erez Lotan
Summit 2016: The way to unified CI/CD using Ansible / Hadar Davidovich
Summit 2016: A Brand new Immune System for a Brand New Google Product / Itay Maman
Summit 2016: Handling millions of connections in Cowboy using Elixir / Joey Feldberg
Summit 2016: How to make a Lisp interpreter in 56 languages / Dov Murik
Summit 2016: Dealing with "Conway law" / Guy Doulberg
Summit 2016: Get a life - Rethinking work life balance / Michal Brosh
Summit 2016: Is it good enough? or - what is MVP? / Moran Shimron
Summit 2016: Early Detection of Cancer: Using NLP Classifiers to Analyze Medical Research Papers / Limor Lahiani
Summit 2016: Software Punk: examining controversial ideas in Software Development / Lior Bar-On
Summit 2016: Subdivision - a tiny library for building highly decoupled and modular web apps / Boris Kozorovitzky
Summit 2016: Social Soccer Betting Application / Roi Ezra
Summit 2016: Farmers application (מהחקלאי) / Shlomi Zadok
Summit 2016: Front End Test Automation: past, present and future / Oren Rubin
Summit 2016: Digital Information Preservation / Ran Levy
Summit 2016: The Next Linux Superpower: eBPF Primer / Sasha Goldshtein
Summit 2016: Performance Limitations of React Native and How to Overcome Them / Tal Kol
Summit 2016: A call out to engineers to become product managers / Yuval Samet
Summit 2016: How to (really) create transparency / Iris Shoor
Summit 2016: Mobile Development in 2016 - A song / Yoni Tsafir
324 Bumpers 41

Summit 2017 Call for Papers

323 Mozilla

322 Security essentials for startups

321 Bumpers 40
320 Bumpers 39
319 Bumpers 38
318 Bumpers 37

317 Zusammen with Zohar Sacks

316 Yet another session with Shlomi Noach
315 Bumpers 36
314 Bumpers 36

313 Carburetor 23 - NFV - network virtualization
312 Bumper 34
311 Bumpers 33

310 FED School with Serge Krul
309 Bumpers 32

308 Wisdo

307 Bumpers 31

306 re:dash

305 The ops school

304 Reversim Summit 2016

303 Redis news
302 Bumpers 30

301 Where do developers go at 40 or 50?

300 Carburetor 22 - InsightEdge
299 Fogcast 25 - Package managers

298 The history of visual object detection

297 Fogcast 24 - Lambda

296 NLP with Yoav Goldberg

295 Bumpers 29

294 Fogcast 23 Hackathons

293 D with Shahar Shemesh
292 Bumpers 28

291 Raspberry Pi

290 Bumpers 27

289 Fogcast 22 Graph Databases

288 Carburetor 21: Predictions for 2016

287 Search, with Ronny Lempel

286 (No) Cloud infrastructures Data infra, with Alon Elishkov

285 A podcast about Nothing
284 Bumpers 26

283 Totango

282 The R in RnD (continue)

281 Fogcast 21 - Optimistic v/s Pessimistic developer

280 Cloud Vendor Series - HA/HR with AWS

279 Digital Ocean
278 Bumpers 25

277 Scientific Python

276 Fogcast 20 - queues
275 Bumpers 24

274 Cloud vendor series - IoT with MS Azure

273 The Research in R&D

272 Cloud vendor series - Mobile Backends with Google Cloud Platform

271 Cloud Vendor Series - HA/DR - Vendor Free - outbrain

270 Cloud Vendor Series - Big Data and Analytics with AWS
269 Analytics and Big Data with Google Cloud
268 Bumpers 23

267 Cloud Vendor Series - Mobile Backends with AWS

265 Groovy

264 Cloud Vendor Series - Google Cloud - HA/DR and multi-cloud

263 WFH

262 Fogcast 19 - Flights

261 FPGA

260 You Gotta Love Frontend - Conference

Summit 2015: The hall of shame
Summit 2015: How to build a succesful opensource community / Ohad Levy
Summit 2015: JTLocalize - an iOS localization framework / Matan Eilat
Summit 2015: Eating the cake (open source) while leaving it whole (keeping your core business closed source) / Ori Hoch
Summit 2015: Accord: A sane validation library for Scala / Tomer Gabel
Summit 2015: gobench :: ApacheBench (ab) on steroids / Uri Shamay
Summit 2015: score – open source workflow engine to automate your docker process / Meir Wahnon

259 Bumpers - wayback
Summit 2015: Batyam - a simple, stronger, collaborative dashboard / Sella Rafaeli
Summit 2015: Putting your local Israeli Open Source community on the international map / Miriam Schwab
Summit 2015: Build a big data dashboard with Ember.js / Shai Alon
Summit 2015: Same Problems, Different Actors: Symmetry in the Content Discovery Marketplace / Ronny Lempel
Summit 2015: Technical leadership - more impact in less time! / Gili Nachum
Summit 2015: JVM Garbage Collection logs, you do not want to ignore them! / Haim Yadid
Summit 2015: Developers like winning: use gamification to promote code reviews / Tzach Zohar

258 TCE Conference
Summit 2015: Y’all don't know how to interview developers! / Ori Hoch
Summit 2015: Captain's Log - Applying Kaizen & Scrum to become a ninja developer / Asaf Mesika
Summit 2015: Distribution First / Lital Hassine
Summit 2015: HTTP 2.0 in 5 minutes / Ben Maraney
Summit 2015: A newcomer's view of the Israeli Video Games industry / Oded Magger
Summit 2015: Loop into the Javascript Event Loop / Yonatan M
Summit 2015: Superpowers of software development / Yoav Rubin
Summit 2015: Artificial Intelligence - Is anyone building the terminator yet? / Hagai Levin

257 MindCET
Summit 2015: Putting the 'D' in TDD / Shai Yallin
Summit 2015: Scaling up your R&D group / Avi Wortzel
Summit 2015: Magneto - taking our Automated Testing to the next level / Ran Ben Aharon
Summit 2015: Consul - much more than a Service Discovery Tool / Alon Becker
Summit 2015: Continious Deployment with Docker / Ariel Moskovich
Summit 2015: Power Trip with a Power Drill - Monitoring distributed systems with Riemann / Itai Frenkel
Summit 2015: How to Create a Native-Like experience in the Mobile Web / Amit Zur
Summit 2015: Isomorphic Javascript - The Next Big Thing in Web Development / Elad Levy
Summit 2015: Should you move from Objective-C to Swift? / Yoni Tsafir
Summit 2015: The ugly truth: 11 ways to learn what users really think about your product / Iris Shoor
Summit 2015: Developing a public API / Yonatan Maman
256 Bumpers 22
Summit 2015: Confessions of a Java developer that fell in love with the Groovy language / Victor Trakhtenberg
Summit 2015: Microservices and Event-Driven-Architecture with Clojure and Kafka / Nir Rubinstein
Summit 2015: Reactive by Example / Eran Harel
Summit 2015: Scaling with microservices archiretcure and multi-cloud platrofms / Aviran Mordo
Summit 2015: Storm in under a second / Re'em Bensimhon
Summit 2015: Experimenting on Humans - Advanced A/B Testing / Talya Gendler
Summit 2015: 5 Bullets to Scala Adoption / Tomer Gabel
Summit 2015: Interactive Deep Analytics Dashboard / Yaniv Shalev
Summi2015: Programming with Millions of Examples / Eran Yahav
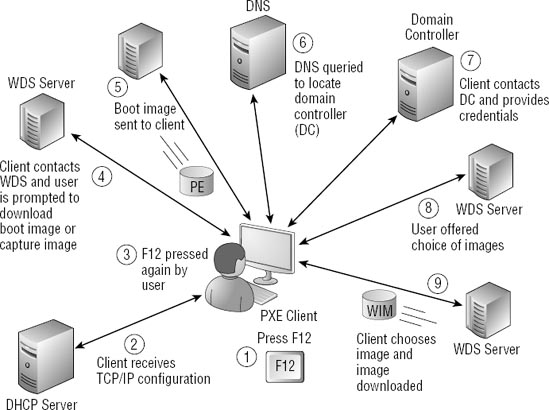
255 Fogcast 18 - Windows Deployment
Summi2015: Refactoring of Legacy Code / Avi Etzioni
Summi2015: Two engineers are walking into a Stand-up Comedy Club / Nir Katz

254 Thunderbolt

253 Fogcast 17 - Deployments
252 - Bumpers 21
251 - Spark your legacy

250 - Fogcast 16 - Trusting products

249 - Carburetor 20 - VMWare
248 Bumpers 20

247 - Carburetor 19 - devopsdays

246 - Gormim

245 - Benefits
244 Bumpers 19
243 Bumpers 18
242 Fogcast 15 - API Versioning

241 Open Source Legal

240 WeWork

239 Carburetor 18 - Docker vs PaaS - How Docker disrupt the PaaS space

238 Organizing Developer Events - devopsdays and more
237 Bumpers 17

236 Python and NodeJS tools in Visual Studio

235 Flat Dev Organizations

234 Fogcast 14 - My bug!

233 Carburetor 17 - Microservices
232 Bumpers 16

231 Carburetor 16 - Software Defined Operator

230 Fogcast 13 - working parents

229 Fogcast 12 - gulpjs

228 - Scalapeño

227 Carburator 15 - Adrian Cockcroft
226 Bumpers 15

225 HR, recruiting etc

224 ASP.NET vNext

223 Fogcast 11 - Redis

222 - Carburetor 14 - From Java to Python

221 Fogcast 10 Session Management

220 Technology Shift
219 Bumpers 14
Summit 2014: Latency & Client Side Performance / Gilly Barr

218 - Propagator

217 Fogcast 09 - Fullstack devs

216 - AppsFlyer and Clojure
Summit 2014: Automating Machine Learning: from Lab to Production / Ofer Ron
Summit 2014: A real life continuous integration war story / Gil Hoffer
Summit 2014: Scaling Extending and Expanding your application through messaging / Avi Tzurel
Summit 2014: Scaling the R&D While Maintaining Quality / Aviran Mordo
Summit 2014: DevOps redux / Tomer Gebel

Summit 2014: The Hall of Shame
Summit 2014: Postgres + JSON - the best of both worlds? / Hadar Davidovich
Summit 2014 Panel: Moving Fast in Big Companies
Summit 2014: Code Review - Just Do It! / Avi Etzioni

215 - Carburetor 13 - SSD Databases
Summit 2014: Open Source in Israel - Mordor / Uri Shamay
Summit 2014: Open Source in Israel - Celestial / Ronen Narkis
Summit 2014: Open Source in Israel - Mean / Lior Kesos
Summit 2014: Open Source in Israel - Go Proxy / Elazar Leibovitch

214 Arduino
Summit 2014: Open Source in Israel - Ground Control / Dotan Nahum
Summit 2014: Open Source in Israel - Sneakers / Dotan Nahum
Summit 2014: The unbearable lightness of Meteor web apps development / Udi h Bauman
Summit 2014: Scaling out Datastores and the CAP Theorem / Yoav Abrahami
Summit 2014: Building Company Culture for Scale / Ori Lahav
Summit 2014: Making drones dance / Aviv Cnaan
Summit 2014: The E2E SW Engineer / Lior Cohen

213: Fogcast 08 - Testing (cont)
Summit 2014: Top video lectures that any developer should see / Yoav Rubin
Summit 2014: Monads in 5 minutes! / Shay Elkin
Summit 2014: Rails Girls in Tel Aviv / Inbal Gilai
Summit 2014: The Technology and Psychology of Scraping / Arik Galansky
Summit 2014: A Hypervisor, a container and a zeroVm were sitting in a restaurant, suddenly an application entered / Dor Laor
Summit 2014: Alive and kicking - evolving QA to meet future challenges / Omri Lapidot
Summit 2014: Taboola's experience with Apache Spark / Tal Sliwowicz
Summit 2014: Engineering your culture: how to keep your engineers happy? / Oren Ellenbogen
Summit 2014: Proper Unit Tests / Omer Lachish
Summit 2014: 10 Reasons to be excited about Go / Dvir Volk
Summit 2014: Why Aren't There More Female Entreprenours / Dafna Mordechai
Summit 2014: Introduction to Deep Learning / Al Yaros
Summit 2014: Panel: Lean Startup
Summit 2014: UX for my dad / Boaz Katz
Summit 2014: Continuous deployment made easy with Codeine / Ohad Shai
Summit 2014: The Public Knowledge Workshop - from a script scraping knesset votes to vibrant community of Israeli open-{source,gov,knowledge} projects / Ofri Raviv
Summit 2014: Tipa.li - how we built a better Open Source alternative to a 120K NIS government mobile app in 48 hours. And how you can too! / Nir Yariv
Summit 2014: The making of a new open OS, code talks and bulshit walks / Dor Laor
Summit 2014: re:dash a new way to query, visualize and collaborate on data inside an organization / Arik Fraimovich
Summit 2014: A closed-source developer's journey into open source / Allon Mureinik
Summit 2014: Functional programming in Javascript / Yoav Rubin
Summit 2014: Concurrency and Multi-Threading Demystified / Haim Yadid
Summit 2014: Coding marketing: How I converted our dev team into marketers / Iris Shor
Summit 2014: How to make your kids love programming / Ran Levi
Summit 2014: The query which is the peak of my career / Shlomi Noach
Summit 2014: Tools & Tricks for building a remotie friendly team / Joey Simhon
Summit 2014: Drop your weapons / Moran Shimron
Summit 2014: Docker - containers are the new virtualization / Shlomi Fruchter
Summit 2014: Random Hack of Kindness / Lital Hassine
Summit 2014: How to Increase Your Brain's Cache Hits? / Yaron Wittenstein
Summit 2014: Software Architecture / Yoav Abrahami
Summit 2014: Retrospective to the Hummus Manifesto / Michael Eisenberg
Summit 2014: Creative Thinking in KPI Definition / Danya Swartz
Summit 2014: Scale up your thinking: Reactive programming with Scala and Akka / Lior Shapsa, Yardena Meiman
Summit 2014: Evolutionary and Genetic Algorithms / Tzofia Shiftan

212 Fogcast 7 - Testing (or not)

211 OSS Licensing

210 Bumpers 13

209 - Carburetor 12 - Devops Orchestration
208 Fogcast 06 - the many ways to scale
207 Fogcast 05 - Selecting technology stack (cont)
206 Fogcast 04 - Selecting technologies
205 Bumpers 12

204 Fogcast 03 - Loggins

203 Fogcast 02 - MeteorJS

202 Carburetor 11

201 Fogcast 01
199 Bumpers 10

198 OneRing

197 Final Class 35 Continuous Deployment in Large Companies

196 Carburetor 10 - DevOpsDays TLV 2013
195 Final Class 34 - Anti Patterns

194 Swagger
193 Bumpers 9
192 Bumbers 8 - take 2

191 Carburetor 9, openstack, oscon
190 Final Class 32: Web APIs
189 Bumpers 7
189 Bumpers 6

188 mean.io

187 Final Class 31 - ThoughtWorks Radar 2013
185 final class 30 caching
184 Carburetor 8 Build Your Own PaaS
183 Xamarin
182 Varnish
181 Carburetors 7
180 Scala Conf

179 Station Configuation

178 Boxen, Vagrant and friends
177 Bumpers 5
176 Monitorama
175 Final Class 28
Summit 2013: Vagrant and Puppet, your ops sketching board, by Ronen Narkis
Summit 2013: To provide & serve...content, by Royi Benyosef
Summit 2013: The Mathematical Side of User Happiness, by Roee Adler
Summit 2013: Streaming BI, by Haggai Sachar
Summit 2013: River - A data flow management infrastructure, by Harel Ben Attia
Summit 2013: Play framework, by Andrew Skiba
Summit 2013: Panel Startups, moderated by Danny Cohen
Summit 2013: Panel Final Class, moderated by Gili Nachum
Summit 2013: Panel Are we an industry or just a bunch of companies, moderated by Ori Lahav
Summit 2013: Lazy Developer Zen, by Eran Sandler
174 AngularJS
173 Carburetors 6
Summit 2013: Kenshoo and the GreenPlum, by Lior Harel
Summit 2013: Introduction to node.js, by Ran Mizrahi
Summit 2013: I want to cache it. Now, by Dimitri Krassovski & Eugene Olshenbaum
Summit 2013: HTML5 APIs For Modern Web Apps, by Ido Green
Summit 2013: How To Fuckup, by Yosi Taguri
Summit 2013: Functional OOP, Clojure style, by Yoav Rubin
Summit 2013: Ember.js for Large Scale Applications, by Oren Rubin
Summit 2013: Doing Lean in B2B, by Oren Raboy
Summit 2013: Distirbuted - reinventing the workplace, by Yoav Farhi
Summit 2013: Defensive Programming, by Lior Sion
Summit 2013: Data, Design, Meaning, by Idan Gazit
Summit 2013: Continuous Deployment at scale, by Itai Hochman
172 JS Testing
Summit 2013: Building Network and Battery Efficient Apps, by Ran Nachmani
Summit 2013: Building lightweight products, by Uri Lavi
Summit 2013: Building web infrastructure for 10M users, by Yoav Abrahami
Summit 2013: Products have feelings too, by Iris Shoor
Summit 2013: Big Data in the Cloud, Nati Shalon
Summit 2013: A Successful Git branching model with git-flow, by Igal Tabachnik
Summit2013: Android App to the challenge, by Udi Cohen
Summit 2013: How Scala Promotes TDD
Summit 2013: QA without QA, Uri Nativ

171 MySQL 5.6
170 Bumpers 4

169 Carburetor 6 - OpsWorks
168 Final Class 27: POC

167 carburetor 4: devopscon
166 - Bumpers 3

165 Automattic, the distributed company

164 Carburetor 3
163 Final Class 26 - Yearly wrapup 2012

162 Software Lead Weekly
161 Bumpers 2

160 KVM

159 Bumpers 1

158 Carburetur 2, open source clouds and more

157 Final Class 25 Automated Testing

156 Software Patents פטנטים בתכנה

Promo - Plugs/Sparks/Bumpers

154 Hasadna

153 Final Class 24 ThoughWorks Radar

152 - Carburetors #1 - Sandy

151 - HTML5 and CSS3 news

Final Class 23: IDEs
149 Final Class 22: Personal Development
148 Final Class 21 Working Extra

147 BI with Haggai and Erez

146 github

145 CouchBase
144 final class 20 Developer Onboarding
143 Hamakor עמותת המקור
142 Final Class 19 Code as Conversation

141 Object Pascal with Ido Kanner

140 Dart with Ido Green

139 ember.js
138 Final Class 18 - past, present, future

137 binpress

137 Nir Katz

135 final class 17 Software Deadlines
134 The Zen of Python

133 The Junction

132 Sasson

131 uijet

130 Windows 8

129 Backbone.js

128 Final Class 16 - Simplicity

127 Gogobot

126 Android 2

125 The Lean Startup
Final Class 15 OOP FTW
123 final class 14

122 - algo trading
119 final class 13

121 Kickstarting invi

120 android
118 Go Lang with Miki Tebeka
116 final class 12

117 Google Developer Day

115 Clojure

114 ZooKeeper
110 final class 11

113 ChromeOS with Ido Green

112 .net with Ido Ran

111 HTML5 with Ido Green

108 Yoav Avrahami - Wix
109 Final Class 10
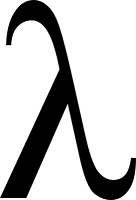
107 lambda
106 final class 9

105 Marketing with Shira Abel
104 final class 8
102 final class 7

103 Foreman

101 bitorama and nodejs

100 פרק מאה

099 - מאסטר שף - שימוש ב- chef ב - Outbrain.
098 Ruby with Reuven Lerner

097 Final Class 6

096 Web Performance

095 Final Class 5

094 mysql 5.5
092 Continuous Deployment at outbrain
093 final class 4

091 Datacenters 2

090 Sgura 3

089 soluto

086 Software Axioms
088 Final Class 2
087 מחלקה סגורה

085 Application Protocols

084 The Lift Web Framework
083 Outbrain Operations

082 scalebase

081 software craftsmanship

080 מניפסט החומוס - hummus manifesto

079 fooducate

ILtechTalks

077 רשתות תקשורת

075 Continuous Deployment

074 Startup Weekend

073 UX with Martin
076 outbrain ואלגוריתמים

072 ATDD

071 iphone

070 yazamiyot

069 Nati Shalom, Gigaspaces

067 הקנטינה

063 אבולוציה של שפות תכנות

068 פאנל בטכניון

066 agile and kanban

065 hadoop

064 mobile and android
062 נשים בתעשייה

061 sxsw

060 שאלות ותשובות

059 שפת שאילתות אינטגרטיבית LINQ

058 אבטחת מידע בתכנה software security

057 - לא רק אס קיו אל חלק 2 וקסנדרה- nosql+cassandra

056 - לא רק אס קיו אל - nosql
055 - פודקאסט מספר 55 - ימולדת!!!

פודקאסט מספר 54 - Platonix

פודקאסט מספר 53 - מערכות ניהול תוכן CMS
פודקאסט מספר 52 -הקלטה משותפת עם ברק על outbrain,
פודקאסט מספר 50 -האצת תכנים, CDN

פודקאסט מספר 51 - Startup Weekend
פודקאסט מספר 49 - סטארט-אפ זיג-זג
פודקאסט מספר 48 - איגוד האינטרנט הישראלי ו- W3C
פודקאסט מספר 47 - Scalability למתחילים
פודקאסט מספר 46 - ריבוי חוות שרתים
פודקאסט מספר 45 - Java References

פודקאסט מספר 44 - סופ"ש סטארט-אפ
פודקאסט מספר 43 - שמישות 2.0 - עם ברק דנין
פודקאסט מספר 42 - אוטו זבל...

פודקאסט מספר 41: mobile web חלק ב
פודקאסט מספר 41: mobile web חלק א
פודקאסט מספר 40 - מי רוצה להתקבל - לעבודה אצל יואל
פודקאסט מספר 39 - עיצוב מוצר והתעשיה הבטחונית
פודקאסט מספר 39 - Maven
פודקאסט מספר 37 - נגישות אתרים #2
פודקאסט מספר 36 - המשכיות עסקית - שיום הדין... ימתין
פודקאסט מספר 35 - איגוד האינטרנט הישראלי ופרוייקט OPEN
פודקאסט מספר 34 - נגישות אתרים

פודקאסט מספר 33- אבטחת מידע
פודקאסט מספר 32- ממשקי משתמש (2)

פודקאסט מספר 31 - התכנית הבלתי מתוכננת
פודקאסט מספר 30 - שכתובי קוד (2)
פודקאסט מספר 29 - הון סיכון
פודקאסט מספר 28: mysql

פודקאסט מספר 27 - תשתיות ג'אווה סקריפט ו- Ext.Js

פודקאסט מספר 26 - על אתרי תוכן ופיתוח מוצר
פודקאסט מספר 25: מרכזי מידע data centers
פודקאסט מספר 24 - המפתח המתפתח
פודקאסט מספר 23 - מערכות ניהול קוד
פודקאסט מספר 22 - על מוצר אינטרנטי ושימושיות

פודקאסט מספר 21 - שעה קלה על כלכלה
פודקאסט מספר 20 - DJango

פודקאסט מספר 19 - PHP

פודקאסט מספר 18 - Erlang

פודקאסט מספר 17 - Key-Value Databases

פודקאסט מספר 16 - Scala

פודקאסט מספר 15 - ASP.NET
פודקאסט מספר 14 - Ruby on Rails

פודקאסט מספר 13 - scalability עם ניר יפת

פודקאסט מספר 12 - תשתיות פיתוח לאינטרנט - חלק ב'
פודקאסט מספר 12 - תשתיות פיתוח לאינטרנט - חלק א'
פודקאסט מספר 11 - טוויטר

פודקאסט מספר 10 - SundaySky

פודקאסט מספר 9 - TDD - תיכנות מונחה בדיקות

פודקאסט מספר 8 - Debugger - ידידו הטוב של המפתח... או שלא?

פודקאסט מספר 7 - שכתובי קוד
פודקאסט מספר 6 - עקרונות התכנות - יצירתיות

פודקאסט מספר 5 - גאדג'טים ווידג'טים

פודקאסט מספר 4 - אנשי תכנה
פודקאסט מספר 3- הלקוח הרזה - Thin Client
