היום אנחנו הולכים לדבר עם אסף מחברת Outbrain על נושא שנקרא AutoML - תיכף נדבר על מה זה ועל מה זה עושה.
ואנחנו, כרגיל, באולפנינו הביתי אשר בכרכור - סגר מספר 3 עבר עלינו בשלום, החיסונים כבר אצלנו ואנחנו נתנים גז . . .
(אורי) כן - חוץ מזה שפתאום הופעת עם משקפיים . . .
(רן) רק לאותיות הקטנות.

אז אסף - בוא קודם נכיר אותך: מי אתה? מה אתה עושה ב-Outbrain? אחר כך כמובן נדבר על מה זה AutoML ולמה זה מעניין אותנו.
(אורי) זה סוג של אוטו . . .
- (אסף) אז אני אסף קליין, והיום ב-Outbrain אני מנהל קבוצה של מהנדסים ו-Data Scientists
- ספציפית, ה-Task הגדול שלנו זה לבנות את מערכת ה-CTR, זאת אומרת - היכולת שלנו לחזות את ההסתברות ש-User יקליק על אחת ההמלצות שלנו.
- בהשכלתי אני בעל תואר שני במתימטיקה ובמדעי המחשב, עבדתי בעבר בכמה תפקידים, גם כמה תפקידי Engineer וגם בתפקידי אלגוריתמיקה שונים ומשונים בכמה חברות.
- ב-Outbrain אני כבר כשש שנים - וואו, הזמן עף כשנהנים . . .
(רן) מעולה . . . עד כמה בכלל חשוב כל הסיפור הזה של CTR ב-Outbrain? למה בכלל זה מעניין AutoML או Machine Learning באופן כללי ב-Outbrain?
- (אסף) אני אתייחס חלק הראשון של השאלה שלך בהתחלה - CTR זה בעצם אבן הבניין - ואני קצת אצטנע - המרכזית במנוע ההמלצה שלנו.
- זאת אומרת - כשאנחנו פוגשים משתמשת באחד מאתרי התוכן שעובדים איתנו, בעצם כדי להבין מהי ההמלצה הכי נכונה עבורה יש לנו איזשהו מודל, Predictor, שאמור לבוא ולהגיד מה ההסתברות שעבור אותה היוזרית - פריט התוכן הספציפי יעניין אותה כרגע, בהקשר הנתון שבו היא נמצאת.
- וזה בעצם השיקול הכי משמעותי לגבי איזו המלצה היא תראה.
- (אורי) חלק בלתי נפרד מה . . . מוצר ההמלצות, התפקיד שלו הוא להגיש תכנים מעניינים וליצור את המוטיבציה לעבור אל התוכן הזה.
- זה נמדד אצלנו בקליק - כמו שמקליקים על תוצאת חיפוש בגוגל או על תוכן שמוגש בפייסבוק - אנחנו עושים את זה “באינטרנט הפתוח”.
(רן) אז אפשר להגיד שהתפקיד שלך ושל החבר’ה שלך זה חלק מה - Core Value Proposition של Outbrain, חלק מהמנוע המרכזי של Outbrain - ואתם עוסקים בעיקר בתחום של Machine Learning.
פה ספציפית אנחנו רוצים לדבר עלך הקונספט של AutoML - אז בוא אולי נתחיל לדבר על מהי הגדרת הבעיה, למה בכלל AutoML? למה זה דומה? איפה נתקלת בזה לראשונה?
- (אסף) אז שנייה . . . AutoML, אני חושב, זה Buzzword מאוד נפוץ היום בכל התעשייה - ואני לפחות אתן את ה-Take שלי על כל הדבר הזה.
- אני חושב שכל מי שהתנסה אי פעם בפיתוח מערכת מבוססת Machine Learning, שצריך גם לשים אותה ב-Production ואמורה לשמש משתמשים אמיתיים באילוצים אמיתיים, חווה תסכול מסויים או קושי מסויים, ואני אנסה טיפה להרחיב, אם אני מדבר יותר מדי אנא עצור אותי . . .
- לרוב, כשאנחנו חושבים אל איזשהו Task שהוא סביב Data Science אז יש לנו כמה שלבים לדבר הזה -
- כ-Data Scientist אנחנו לרוב מקבלים איזושהי בעיה, איזשהו Data-set, איזושהי משימה - לרוב זה מתחיל באיזשהו מחקר, Offline-י, שבו אנחנו עוסקים באקספלורציה (Exploration) של הדאטה, הבנה של הבעיה, הבנה של המימדים הרלוונטיים וכן הלאה.
- אם התמזל מזלנו, אחרי עבודה קשה, אנחנו מגיעים לאיזשהו מודל שאנחנו מרוצים ממנו
- היה נחמד אם זה היה הסוף - אבל המעבר ממודל שעובד לנו לוקאלית על המכונה שלנו, על ה-Data set שיש על המכונה, למשהו שרץ ב-Production הוא מעבר, בוא נגדיר את זה כ”לא טריוואלי” . . .
- אני יכול קצת להרחיב?
- (רן) כן . . . באופן טיפוסי, אתם בונים את המודל על המכונות הפרטיות, או שהמכונה זה רק כמשל?
- (אסף) כמשל . . . יש לי פואנטה בסוף . . .
- אז סבבה - אנחנו באים לשים את המודל ב-Production, ולא תמיד גם שם החיים פשוטים, כי Data Scientists ואלגוריתמיקאים אוהבים לעבוד ב-Stack שלהם, לרוב ב-Python . . .
- אני כמובן מכליל, אבל Python זה לרוב ה-Stack הנפוץ, עם כלים וחבילות ו-Libraries שמאוד נוחים לנו כ-Data Scientists - ולא תמיד ה-Stack ב-Production שלנו כתוב גם הוא ב-Python, ולכן לא תמיד זה קל, לדוגמא, לקחת את ה- XGBoost המדהים שבנינו ולשים אותו במערכת ה-Production שלנו.
- במיוחד אם אני מתייחס שנייה ל-use cases של Outbrain, שבהם נדרשים SLA מאוד קשיחים -
(רן) אז אולי בשביל ה-Context, אני בתפקיד שלי ביום-יום גם מנהל קבוצה של Data Science ב-AppsFlyer ואני גם מזהה עם הכאבים שלכם והם חוזרים גם אצלנו.
אוקיי - אז מה עושים? Data Scientist אוהב לעבוד ב-Python, אוהב לכתוב XGBoost - וזהו, אחר כך נגמר העניין. אבל בכל אופן - ה-Business רוצה שניקח את המודל הזה ונשים אותו ב-Production, אז מה עושים?
- (אסף) אז האמת היא שיש לי פה עוד פואנטה, רן, אני מצטער שאני ככה נותן לך קונטרה, אני אשמח לענות על זה - בוא נניח שהתגברנו על הבעיות האלה, אני חושב שיש מגוון של דרכים לתת מענה לדבר הזה
- אם זה כל מיני חבילות שיודעות לקחת את המודל XGBoost ולהגיש אותו בחבילות שונות ומשונות, או אולי אתה ממש רוצה להתאבד ובא לך לממש את זה ב-++C כדי בכלל לחוות זמני תגובה מהירים
- אבל אפילו אם התגברת על המהמורה הזאת, גם כשהמודל שלך מתחיל לשרת את ה-Production, גם שם אתה מתחיל לחוות Friction . . . אני אתן שתי דוגמאות ברשותך -
- למשל, משהו שאני חושב שהצוות שלי בזבז - השקיע! - עליו משהו כמו שלושה שבועות כשהמודל שלנו היה ב-Production וזה שאתה פשוט מקבל פרדיקציות (Predictions) שהן לא הגיוניות . . .
- וכשאתה בא לחקור את זה אתה מבין שהדאטה שראית בזמן ה-Training הוא לא הדאטה שאתה רואה בזמן ה-Serving בהמון מובנים . . .
- סתם אנקדוטה - יש לך דאטה שמגיע לך ב-Serving באיזשהו API והוא פורמט בצורה אחת, אבל כשהוא נכתב כבר ל-Data Lake, ל-Database שלך, על ה-Hive שלך או Whatever [כבר יצא כזה שירות של AWS? שם טוב], הוא מפורמט (Format) קצת אחרת - נגיד שהוא עובר ל-Lower case, ועכשיו המודל שלך ראה Upper case ב-Training וב-Serving הוא רואה Lower Case ואוי ואבוי . . .
- זה עוד סוג של Friction
- (רן) אתה יודע מה? אם אנחנו כבר מערימים קשיים, אז תרשה לי להערים קושי נוסף: יש את כל הסיפור הזה של Feature engineering, שלפעמים הוא קורה ב-Offline באופן שונה ממה שקורה ב-Online, וזו עוד מהמורה שככה צצה וצריך לעבור . . .
- (אסף) לגמרי . . . בוא ככה נבנה את המוטיבציה אפילו, נעשה פה דרמה יותר גדולה - גם אם התגברנו על זה ובנינו כלים, עכשיו יש לנו מודל ב-Production, ולרוב זה מודל בהתחלה ראשוני, ועכשיו יש לנו צוות של Data Scientists שכל הזמן רוצים לשפר אותו, ולבדוק את הדברים שלהם ב-Production ולראות שהם עבדו - איך אנחנו עושים את כל הזמן? זה בעצם כל הסיפור הזה כפול כל החיים בערך . . .
- (רן) כן . . .
- (אורי) כל החיים כפול כל ה-Data Scientists . . .
- (אסף) אמרת את זה נכון
- (רן) אוי, כבר יש לנו מטריצה, עוד שנייה אנחנו עוברים ל Tesor-ים . . . וגם יכול להיות שמודל שעבד מצויין אתמול אולי יפסיק לעבוד מחר, כי העולם השתנה או כי דברים קרו.
- (אסף) נכון, וזה אחד האייטמים שלי פה שלא דיברתי עליהם - Concept Drift, שזה משהו מאוד מאוד שכיח, במיוחד בתעשיית ה-Ad-Tech, כשה-Marketplace הוא נורא דינאמי.
- (רן) כן - המלצה שאולי הייתה מצויינת אתמול, והדאטה בסדר והכל Lower case והכל בסדר - אבל התוכן השתנה, עולם התוכן השתנה וההמלצה כבר פחות רלוונטית.
- (אורי) אומרים שעם העיתון של אתמול אפשר לעטוף דגים? אז זה בערך . . . זה כבר בעולם ה-Online זה שעם העיתון של לפני עשר דקות אפשר לעטוף דגים.
- (אסף) לגמרי
(רן) בסדר - אז עכשיו אנחנו מוכנים לפתור את הבעיה?
- (אסף) יש איזושהי מנטרה שאני מנסה לחזור עליה במהלך השיחה שלנו - אני חושב שאחד ה-Take aways שלנו מאיזשהו שכתוב מאוד מאסיבי של המערכת במהלך השנה האחרונה הוא שצריך בעצם לאפשר ל-Data Scientist להיכשל מהר . . .
- בטח שמעתם את זה, זה קצת קלישאה, אבל זה נורא נכון.
(רן) אז אתה אומר “להיכשל מהר” . . . לא להצליח אלא להיכשל מהר. מה עומד מאחורי זה?
- (אסף) כל מי שעסק באלגוריתמיקה ו-Data Science, לפחות בי זה היכה לפני כמה זמן, כי - כמה כיף זה לפתח פרויקט תוכנה רגיל? בפרויקט תוכנה רגיל קל לך לראות אם ה-Latency שלך מספיק מהיר, אם הכפתור שלך במקום וכן הלאה . . .
- ב-Data Science זה לא ככה - ב-Data Science לרוב אתה יורה באפילה, ומקווה לטוב.
- לצערי - הרבה מאוד פעמים אנחנו נכשלים, ולכן אם נאפשר בפרויקט ל-Data Scientists שלנו להיכשל מהר, זה יאפשר להם לנסות דברים הרבה יותר מהר, הם לא יפחדו לנסות, יהיו יותר הצלחות, המודלים שלנו ישתפרו וה-KPI העסקיים שלנו יעלו.
(רן) אז בוא נסתכל, נגיד, על דוגמא - יש לך איזשהו מודל המלצות, וחלמת בלילה על פיצ’ר חדש: “נגיד שכל אות שנייה היא ב-Capital אז זו הולכת להיות המלצה מצויינת!” - ועכשיו אתה רוצה לבדוק האם זה הולך לעבוד.
אם יקח לך חודש לבדוק את כל הסיפור, אתה תספיק לבדוק אולי, עד שיפטרו אותך, משהו כמו שניים או שלושה רעיונות, ואז יגמר לך הזמן, Game Over; אבל אם אתה נכשל מהר, ולוקח לך יום או חצי יום לבדוק את הרעיון המטורף הזה אז אתה תספיק לבדוק עוד ועוד, ובסופו של דבר תגיע דווקא לרעיון קצת יותר מוצלח.
- (אסף) נכון - ואם תיקח את זה אפילו יותר קיצוני, אם תספיק לבדוק בשלושה ימים 20,000 אפשרויות להוספת פיצ’ר כזה או אחר, בפורמולציות כאלו ואחרות, זה אפילו יותר טוב.
(רן) אני חושב שיש פה שני מושגים שהם אולי דומים - אחד מהם זה AutoML והשני זה MLOps - ואני חושב שדיברת על שניהם . . . בוא נגדיר את שניהם ונראה מה כל אחד פותר.
- (אסף) אז באמת אני אעשה Zoom-out ואתייחס למה שאמרת - באיזשהו מקום אני חושב שההבנה היא, לא רק אצלנו אלא באופן כללי, שיש איזשהו יתרון להפרדה בין ניסויים ב-Offline לבין ניסויים ב-Online, ב-Serving.
- זאת אומרת - בסוף היום, ההוכחה שהצלחת לעשות משהו מועיל באיזור האלגוריתמי, באיזור המודל, הוא שאתה שם, במקרה שלנו, איזשהו A/B Test ומוכיח שה-KPI העסקיים במודל החדש שייצרת עולים על המודל הקודם - וזה באמת ה-Online.
- בעצם, כל היכולת לעשות אורקסטרציה (Orchestration) לסיפור הזה - לעלות את הA/B Test בצורה נוחה, לשים את המודל ב-Production בצורה נוחה - אני חושב שזה יותר באיזורים של ה-MLOps.
- לעומת זאת, כמובן שלכל A/B Test או לכל ניסוי Online-י יש Overheads, יש תקורות - ולכן אם אנחנו באמת רוצים להיות יעילים אנחנו צריכים לאפשר לעשות ניסויים Offline, כלומר - איזושהי סביבה שבה ה-Data Scientists שלנו יוכלו לחקור את הבעיה ולחקור כל מיני היפותזות שיש להם בצורה מהירה ויעילה, בעזרת כלים שנותנים להם להתרכז בעבודת ה-Data Science ופחות באספקטים טכניים שתמיד הם חלק מהחיים שלנו.
- אולי האוטומציה הזו, או כל מיני כלים שמאפשרים את האוטומציה הזו - אפשר לתייג אותם בתור AutoML.
(רן) לצורך העניין, חשבתי על הפיצ’ר המטורף שלי שבו כל אות שנייה היא Capital letter וזה הולך להיות פצצה - ועכשיו אני מתלבט: האם אני רוצה לדחוף את זה לתוך XGBoost או לתוך רשת ניורונים - ואם כן אז כמה שכבות או כמה ניורונים, או כמה עצים הולכים להיות בתוך . . . מה העומק של ה-XGBoost.
אם אני עושה את כל זה בצורה סדרתית, כנראה ששוב זה יקח לי כמה ימים טובים, אולי חודש, לבדוק את כל אלו - מה ה-AutoML נותן לנו?
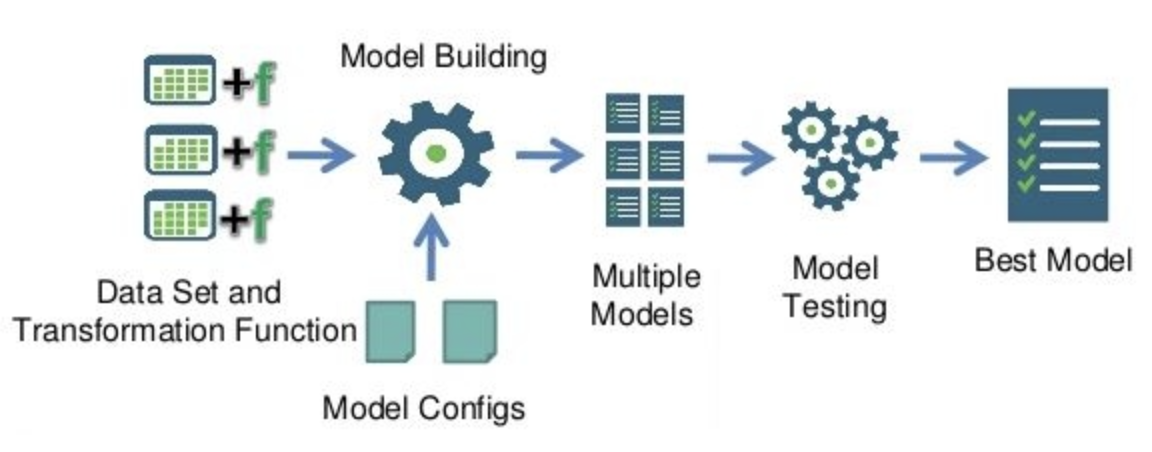
- (אסף) בעצם כלי AutoML מאפשרים לך לבדוק את ההיפותזות האלו בצורה אוטומטית, ווכמובן בסוף נותנים לך איזשהו Audit trail - היכולת להבין עבור כל אחת מההיפותזות או הדברים שרצית לבדוק, עד כמה הם טובים.
- לרוב זה בעזרת איזשהו Proxy - זה לא יהיה ב-Business KPI שלך אלא איזשהו Proxy ל - Business KPI.
(רן) ראיתי כלים כאלה Out there - יש כלי כזה ל-AWS ויש כלי כזה ל-GCP - מה אתם עושים? כתבתם אחד משלכם?
- (אסף) כן . . . תראה, אני חושב שיש . . . קודם כל כתבנו משהו משלנו, והוא תפור באמת לבעיה שלנו, אני יכול טיפה לדבר למה . . .
- המודל שלנו, לרוב . . . כדי להגיד משהו על טיב של מודל כזה או אחר, למשל בדוגמא של רן - האם הוספנו פיצ’ר כזה או פיצ’ר אחר, אז עד כמה המודל מתפקד בצורה טובה? - לדבר הזה נדרש די הרבה דאטה.
- הכלים, לפחות אלו שאנחנו מכירים, פחות יודעים להתמודד עם כמויות הדאטה העצומות שנדרשות לבעיה שלנו.
(רן) אוקיי - אז מה, אני, כ- Data Scientist, בא בבוקר ואומר: “אני רוצה להריץ את שלושת האלגוריתמים האלה, כל אחד עם קומבינציה של 10 פרמטרים שונים”, וזהו - הולך לשתות קפה, חוזר ויש לי תוצאות?
- (אסף) אה . . . קצת יותר מורכב מזה.
- לרוב יש לנו כל מיני שאלות, היפותזות, שבהן אנחנו עוסקים, וכל Data Scientist לוקח מה-Backlog איזושהי שאלה כזאת
- למשל - האם הוספה של פיצ’ר כזה או אחר תשפר את המודל, ובכמה זה ישפר את המודל
- לרוב אתה צריך לבחור איזשהו Data Set שהוא Offline, כי זה לא נעשה בחלל ריק.
- יש לנו דרך, בעצם, לתרגם, את ההיפותזה הזאת לבעית חיפוש - אני יכול לתת דוגמא תיכף, אבל בסוף היום ב-AutoML יש לנו מנוע חיפוש, והוא מחפש במרחב המודלים שה-Data Scientist מגדיר לו - מחפש בצורה מאוד מהירה ומבוזרת, וזה תלוי בכוח המחשב שאתה שם עליו - אבל בגדול, אחרי כמה שעות אתה תקבל תשובה.
(רן) אוקיי, אז אמרת שאתה רוצה לתת איזושהי דוגמא?
- (אסף) אני מתלבט האם לתת דוגמא מורכבת או . . . מעניינת וקצת מורכבת, שנדרש קצת רקע, או משהו יותר בנאלי?
(רן) מעניינת ומורכבת ונדרש ידע - בוא נצלול!
- (אסף) מצויין - אז בעולם של CTR Prediction, אני אתן דוגמא שהיא יחסית מעניינת.
- אחד המודלים - אמנם מודל בסיסי, אבל עובד לא רע - הוא Logistic Regression
- בגדול, הדאטה שהוא מקבל זה המידע על אותו Listing, וה-Context - למשל: רן כרגע נמצא בכרכור, צופה בדף של Ynet(!) בתוך iPhone 12 (!!) - ומערכת ההמלצה שלנו באה לנסות להבין איזו מבין שלושת הפרסומות שכרגע נמצאות ב-Inventory הכי מתאימה לרן.
- אז בעצם, אם ניקח את כל הדברים שאנחנו יודעים על רן ועל ה-Context שבו הוא נמצא - כרכור, iPhone 12 וכו’ - אז לכל אחת מהפרסומות, נוכל להפוך את זה לבעיית Classification של “מה ההסתברות שרן יקליק על אותו פריט תוכן?”
- בוא נאמר שלמדנו את זה מתוך דאטה היסטורי - וזה בעצם Logistic Regression ל - CTR Prediction על קצה המזלג.
- מסתבר שכמו בהרבה בעיות ב-Logistic Regression, צימודים של פיצ’רים מאוד עוזרים
- זאת אומרת - יכול להיות שלמדנו, אם נגיד את זה למודל, שאנשים בכרכור אוהבים ללחוץ על פרטי תוכן על מכוניות אדומות, לעומת אנשים שגרים בתל אביב שאוהבים משאיות ירוקות.
- (אורי) בדרך כלל ההיפך, אבל . . .
- (אסף) כן, קצת אילתרתי . . . אפשר לתת דוגמא יותר מוצלחת כנראה, אבל הנקודה היא שבאמת צימודים כאלה של פיצ’רים מוסיפים המון לדיוק של המודל
(רן) זאת אומרת שאם מקודם בתיאור שלך של המודל הנחת איזושהי אי-תלות - הוא בכרכור, יש לו iPhone, וזה לא קשור לזה שהוא אוהב או לא אוהב מכוניות ירוקות או אדומות, אבל מסתבר שהמציאות מספרת לנו סיפור אחר, כנראה שיש איזושהי קורלציה ביניהם
- (אסף) נכון - וכאשר אתה מוסיף את הצימוד הזה של מיקום וסוג הפרסומת, בעצם המודל שלך יהיה יותר מדויק.
- אם נחשוב על בעיה מהחיים האמיתיים - אז יש לנו אלפים של פיצ’רים, וכאשר באים להוסיף פיצ’ר חדש ל-Logistic Regression, נשאלת השאלה עם איזה צימודים הוא יעבוד הכי טוב.
- אפילו אפשר לקחת שאלה הרבה יותר כללית - אם יש לנו נגיד אלף פיצ’רים, איזה צימודים אנחנו צריכים להוסיף למודל על מנת שהוא יתפקד בצורה הכי טובה שיש?
- (רן) רק נבהיר פה את המתימטיקה - אם יש לנו אלף פיצ’רים, אז אם נוסיף פיצ’ר אחד ונצמיד אותו לכל האחרים, אנחנו הולכים לקבל פי . . . הרבה פיצ’רים
- כל אחד מחובר לכולם
- (אורי) יהיו הרבה . . .
- (אסף) למעשה, אם הולכים בקומבינטוריקה לאקסטרים - זה C(10,2) - וזה הרבה.
- [10 לא המון, 1,000 כבר כמעט חצי מליון . . . ]
- בעצם די מהר אפשר לחשוב על הבעיה הספציפית הזו כבעיית חיפוש - ואז אם יש לך מנוע חיפוש מוצלח אז תוכל למצוא את המודל המיטבי.
- ברור שמרחב האפשרויות פה הוא אקספוננציאלי, ואנחנו לא אוהבים אקספוננציאלי במדעי המחשב . . .
(רן) שנייה, בוא נבהיר רגע . . .
- (אורי) אנחנו לא אוהבים אקספוננציאלי - ותמיד זה אקספוננציאלי . . .
- (אסף) נכון - ויש פתרונות מהספר, מה-Text book, של איך עושים את זה.
(רן) אז בוא רגע נדבר על למה זה מנוע חיפוש - החיפוש הוא בין השילובים השונים של הפיצ’רים, ולכל אחד מהם יש איזשהו Score, זאת אומרת איזשהו . . אם הגעתי למקום אז אני יודע האם הגעתי למקום טוב או לא.
- (אסף) אז באמת ה-Score, אני חושב שזה המרכז פה ואפשר לדבר עליו, ותיכף אני אצלול בשמחה לתיאור של ה-Score, אבל אנחנו מדברים פה בעצם על מרחב חיפוש אקספוננציאלי, ואפשר להפעיל כל מיני אלגוריתמי חיפוש שרצים על המרחב הזה עם Score, עם יוריסטיקה.
- אם נכתוב תשתית טובה והמנוע חיפוש הזה יוכל לרוץ בצורה מבוזרת על הרבה מכונות, וגם ה-Score הזה ידע להיות מחושב מהר, אז ה-Data Scientist שלנו יהיה מאוד מרוצה כי יוכל בדוק את ההיפותזות שלו מאוד מהר.
(רן) אז בו נעשה רגע שנייה סיכום - אני רוצה להוסיף עכשיו פיצ’ר חדש, אבל הבנו שפשוט להוסיף את הפיצ’ר ה-1,001 זה כנראה לא כזה מעניין כי יש הרבה מאוד קורלציות בין פיצ’רים, אז צריך להבין למי הפיצ’ר שלי קורלטיבי או לא, זאת אומרת - איזה קרוסים (Cross) מעניין להוסיף.
וזה אתה אומר במרחב שהוא אקספוננציאלי, אז את זה צריך לצמצם, שלא יהיה אקספוננציאלי - לא אמרת בדיוק מה זה כן, אבל אני מניח שזה קצת פחות, ובכל אופן כנראה שנקבל עדיין מרחב מאוד מאוד גדול, אפילו שזה לא אקספוננציאלי זה עדיין מאוד מאוד גדול - אז גם את החיפוש במרחב הזה אני רוצה לעשות בצורה יחסית מהירה.
והחלק שהוא Computational expensive בכל הסיפור הזה זה החישוב של ה-Score או משהו אחר?
- (אסף) כן, בדיוק זה המרכז.
- בסוף השאלה הבסיסית היא בעצם, אם שנייה נצלול אפילו יותר עמוק, אז בעצם כל Node במרחב החיפוש שלנו זה איזשהו מודל, עם צימוד כזה או אחר של פיצ’רים או עם שניהם יחדיו - ובעצם אנחנו שואלים עד כמה הוא יותר טוב מכל האחרים.
- ואני קצת אתאר איך אנחנו מחשבים את ה-Score הזה - בעצם ה-Score הזה אמור להיות Proxy מאוד קרוב לדיוק המודל ,ולשם כך אנחנו משתמשים ב-Data set שהוא Offline-י, מאוד קלאסי, שמחלקים אותו ל-Train ול-Test,
- חלק ממנו משמש לאימון המודל - ה-Bootstrap שלו - וחלק אחר לחיזוי הקליקים.
- זה דאטה אמיתי כמובן
- ועל תוצאות הפרדיקציות, כשאנחנו יודעים את ה-Target, אם היה קליק או לא היה קליק, אנחנו מחשבים מדדי דיוק - AUC או מדדים אחרים די סטנדרטיים.
- (אורי) זה ל-Offline
- (אסף) זה ל-Offline כמובן
(רן) ואיך אתה יודע שבאמת הדאטה הזה מייצגת את המציאות הנכונה? אם תיקח את כל הדאטה בעולם אז כן, אבל הבעיה היא שהוא גדול מדי . . .
- (אסף) כן, בגלל זה אני חושב ש . . .לפני כן שאלת אותי למה עשינו פה את כל הפיתוח של משהו שהוא ייחודי לנו, וזה באמת כי כדי לייצר את מטריקה שנותנת לנו דיוק טוב, אנחנו נדרשים לקחת הרבה דאטה -
- אז לרוב אנחנו לוקחים דאטה של שבוע, שזה דאטה של ג’יגות (Gb) בגדול, ועליו אנחנו מריצים את החיפוש.
(רן) הבנתי . . . ובעצם מי שבנה את ה-Framework הזה זה בעצם מישהו בתוך קבוצת ה-Data Science אצלכם?
- (אסף) כן, זה התחיל ממשהו די פשוט וסיבכנו אותו ככל שהדרישות הצטברו . . .
(רן) ככל שנתנו לכם . . .
- (אסף) האמת שלא, האמת ש . . .
- (אורי) זה היה תהליך מדהים, כי התחילו במשהו יחסית פשוט כדי להוכיח את ההתכנות של המודל הזה, ולאט לאט הלכו הוגדילו Scale ודייקו ודייקו את המודל, ונוספו פיצ’רים וגם המודלים המתימטיים השתפרו לאורך הזמן.
- (אסף) כן . . . האמת שהתחלנו עם Vowpal Wabbit, למי שמכיר, ובמהלך הדרך . . .
- למי שמכיר - Vowpal Wabbit זה Logistic Regression ממש מהיר
- ובמהלך הדרך קפצנו במנוע המתימטי למשהו שכתבנו אצלנו בקבוצה, שאנחנו קוראים לו Fwumious wabbit, שזה Field-aware factorization machines נורא נורא מהיר
- (אורי) ממש ממש ממש מהיר
- (אסף) ממש . . .אתם יכולים לראות את הבלוגים אצלנו, ב-Outbrain engineering, כתבנו על זה וגם על AutoML אז תוכלו לראות כמה דוגמאות יותר מפורטות
- (רן) יותר ממכונית ירוקה בכרכור . . .
- (אורי) לא, באמת - יש הרבה דברים שנכתבו בבלוג של Outbrain Engineering ושווה לקרוא שם.
(רן) ופה ספציפית דיברנו על Use case של הוספת פיצ’ר - יש לכם נגיד גם Use cases של בחירת מסווג חדש, או כיוונון של Hyper-parameters במסווג או Use cases אחרים בסגנון הזה?
- (אסף) תראה, בחירת מסווג זה עניין די מורכב, כי המסווגים שלנו, כדי שהם יעבדו כמו שצריך, דורשים המון המון עבודה.
- כיום, למשל, יש לנו איזושהי גרסא שתפורה ל-TensorFlow, ובה אנחנו מנסים כל מיני ארכיטקטורות של רשתות - וכן, זה משהו שהכלי זה יודע לתמוך גם בה.
(רן) אוקיי, אז פה בעיקר דיברנו על AutoML - זאת אומרת, החלק ה-Offline-י - אבל בחלק מהצגת הבעיה גם דיברנו על החלק השני, החלק ה-Online-י, שנקרא לו אולי MLOps? נניח . . . אילו פתרונות נבנו בתחום הזה?
- (אסף) אני יכול לספר לך על הרצוי ועל המצוי . . . בוא נתחיל עם הרצוי
- בגדול, אני חושב שהשאיפה שלנו היא שברגע שיש לך תוצאה טובה ב-AutoML אתה תיהיה, אנחנו קוראים לזה “One click away” מ-A/B Test,
- זאת אומרת - בקליק אחד, או גם שלושה קליקים זה יהיה בסדר . . .
- (רן) שה-CTR שלהם הוא? . . .
- (אסף) 1 . . . 100%
- אבל הרעיון הוא שתוכל להגיע נורא מהר ל - A/B Test, עם כמה שפחות Technicalities
- אם נפרוט שנייה מה זה אומר ”ללכת ל - A/B Test”, אני יכול לפחות לתאר את החווייה שלנו ב-Outbrain, אז אומר לפעמים לעשות שינויים בשכבה שעוטפת את המודלים שלנו, לקחת את הפיצ’ר הזה ולגרום לו להגיע בכלל אל המודל ב-Serving, ויש איזושהי עבודה שנדרשת ב-Production, ואחרי זה להתקין, “לרלס” (Release) את אותו Service שמגיש את המודל, וכמובן שזה אומר לבדוק אותו ולעשות בדיקות SLA ו-Latency ו-Staging, ואחרי זה להגדיר את ה-A/B test . . .
- זו שורה ארוכה של משימות, ובעצם השאיפה שלנו היא לגרום לכל הסיפור הזה להיות אוטומטי.
(רן) נכון להיום, כמה . . . אני זוכר, בהיותי מתחום ההנדסה, שאם מודדים לדוגמא מטריקות (Metrics) כמו Commit to Production - כמה זמן לוקח מהרגע שבוא עשיתי Commit ועד שהקוד הוא Deployed ב100% - לכם יש אילו שהן מדדי זמן כאלה? אם כן, מה הם?
- (אסף) אני חושב ש . . .אין לנו איזה Dashboard של Garfana שמודד את זה.
- כיום יש איזושהי סדרה של פעולות שה-Data Scientist צריך לעשות, יש פרוטוקל מוגדר היטב - זה לוקח בסביבות שעה וחצי.
- ואנחנו שואפים בעצם להפוך את זה לדקה וחצי.
- (אורי) זה למודל חדש, כשגם שינית את ההבאה של הדאטה . . .
- (אסף) לא, לרוב, אם נדרשים שינויים ב - Data Pipeline אם להוסיף APIs אז זה יכול לקחת קצת יותר - אני מתייחס ל - Tweak במודל.
(רן) אוקיי - והחלק, נגיד ה - Post Production - לגלות Drift או תקלות אחרות שיכולות לקרות - איך זה עובד בעצם? סיימתי את ה - A/B Test ועכשיו אני שמח, אני שם את זה ב-Production - מה הלאה?
- (אסף) תראה, יש לנו שכבות שונות של ניטור, ושוב - גם פה יש עוד הרבה עבודה לפנינו.
- בגדול יש לנו כל מיני . . . אני יכול רק לומר שהדברים הקריטיים שגילינו שבהם המודלים שלנו מאוד משתפרים זה שהמודל צריך להיות מאוד עדכני.
- בעצם, המערכת בכל חמש דקות מקבל מודל חדש ב - Production - מאמנת מודל חדש ומכניסה מודל חדש ל-Production.
- וזה די מפחיד . . .
- (אורי) רגע, רגע . . . קודם דיברנו על זה שאנחנו רוצים לאמן כל מיני פיצ’רים חדשים ודברים כאלה, וזה כדי לבנות מודל מסוג חדש.
- עכשיו אתה מדבר על מודל עדכני - זאת אומרת: אותו מודל, כמו שבניתי ואימנתי וזה, רק שאני מאמן אותו בכל פעם על דאטה עדכני בכל חמש דקות.
- (אסף) כן, אז אולי באמת שווה לתת טיפה קונטקסט, אולי קצת קפצתי לזה -
- בגדול, המודלים של ה-CTR שלנו, אם תחשבו על ה-Setting של הדבר הזה, בעצם אנחנו כל הזמן מגישים המלצות,
- ה - Users מקליקים או לא מקליקים על ההמלצות שאנחנו מגישים,
- הדאטה הזה, של על מה הקליקו ועל מה לא מגיע למערכת שלנו אחרי כמה דקות ונאסף ב - Data Lake שלנו
- ובעצם אנחנו יכולים לקחת את הדאטה הזה ולעדכן את המודלים שלנו כרגע ב-Production.
- וגילינו ש-KPI מאוד משמעותי לביצועים של המודל זה מהי נקודת הדאטה האחרונה שהמודל שלנו ראה בזמן ההגשה, ואנחנו שואפים שהזמן הזה יהיה קצר ככל האפשר.
(רן) והסיבה מאחורי זה היא שהתוכן מתחדש? זאת אומרת, מה . . .
- (אורי) עם העיתון של אתמול אפשר לעטוף דגים . . .
(רן) אוקיי . . . בסדר - היו לכם אילו שהן מחשבות על ללכת לכיוון משהו שהוא לגמרי Online? זאת אומרת Reinforcement learning, שממש יעשה את זה “באפס זמן”, או קצת יותר?
- (אסף) אני חושב שיש פה הרבה מקום לשיפור, בעיקר אני חושב שבתחום התשתיתי
- יש כאן דבר אחד שצריך להבין, שיש כאן Trade off -
- אנחנו בעצם מציגים המלצות למשתמש
- המשתמש, יכול להיות שבדיוק כשהגשנו לו את ההמלצה הוא צריך ללכת לעשות פיפי,
- והוא יחזור אחרי חמש דקות ואז הוא נזכר שהוא צריך לשתות קפה
- [זו לולאה אינסופית, דוגמא סטריאוטיפית של מהנדס כלשהו]
- רק אחרי רבע שעה הוא יגיד “וואו - איזו המלצה מדהימה ש-Outbrain נתנו לי!” והוא יקליק על ההמלצה
- ורק אחרי אולי שמונה עשרה דקות נקבל את האינפורמציה על הקליק . . .
- הנקודה היא שיש לנו איזשהו Delay אינרנטי (Inherent) בכמה שאנחנו מחכים לקליק - אבל השאיפה באמת להיות כמה שיותר קרובים.
(רן) אז אתה אומר שכאילו “ה-Watermark” הזה של החמש דקות הוא מספיק קצר כרגע, לפי מה שאתם רואים - כי גם ככה יש את ההתנהגות האנושית הזו של זמני קריאה, זמן הפיפי וזמן הקפה, ואין כרגע סיבה משמעותית לרדת מתחת לזה?
- (אסף) אה - לא, אני אגיד . . .
- יש עדיין איזשהו Delay אינרנטי, כמו שאמרנו, וכמובן שיש את כל ה-Data Pipeline שלנו שגורם לאותו קליק לחלחל למערכת, ל-Updater שלנו - ואת זה אפשר לקצר.
- שם יש לנו הרבה - אבל זו בעיקר עבודה תשתיתית, לגרום ל-Data Pipeline להיות הרבה יותר מהיר.
(רן) הבנתי - גם אם אתה מרלס (Release) מודל חדש כל חמש דקות, אז
- א. יש את זמן בניית המודל, שגם יכול להיות לא טריוויאלי
- אני יכול להגיד שאצלנו (AppsFlyer) זה לוקח סדר גודל של שעתיים, אני חושב . . . או שלוש, לא זוכר.
- (אורי) אז פה, עשינו התקדמות מאוד גדולה בנושא של Real-time data pipelines, וזה עוזר בהמון מקומות.
- (אסף) וודאי - בעצם מה שזה אומר, אם שנייה נחשוב, זה בעצם שהמודלים שמגישים המלצות ב-Production, פוטנציאלית ראו חודשים של דאטה.
- (רן) דרך אגב - האימון הוא כל פעם מחדש, או שזה אינקרמנטלי (Incremental)?
- (אסף) אינקרמנטלי . . .
- (רן) אוקיי - אז זה לא חייב להיות כל כך הרבה זמן, ה-Cycle של האימון.
יש עוד נושא שרצית לכסות, לפני שאנחנו נסיים?
- (אסף) לא, אני חושב שעברתי על כל הרשימה שלי
- (אורי) יש נושא שרצית לכסות לפני שאנחנו אומרים שאנחנו מגייסים Data Scientists?
- (אסף) אה, נכון . . . אנחנו מגייסים!
- אנחנו מגייסים אנשים, תסתכלו בדף המשרות שלנו
- ואם מעניין אתכם קצת לקרוא יותר על הדברים שדיברנו כרגע אז כנסו לבלוג של Outbrain Engineering או ב - Medium ל - Outbrain Engineering ותמצאו שם תוכן מעניין.
(רן) מעולה - בהצלחה בהמשך הדרך ותודה רבה.
(אסף) תודה שאירחתם אותי.
הקובץ נמצא כאן, האזנה נעימה ותודה רבה לעופר פורר על התמלול